

Dans cet article technique, l’équipe de notre département Data & Innovation vous propose une architecture permettant le traitement des données en temps réel tout en respectant une stratégie de gouvernance de données.
Après avoir brièvement rappelé les principes de la gouvernance de données et les principales caractéristiques d’un framework de gouvernance, nous verrons une solution type prise dans le cadre d’architectures basées sur des événements (EDA). Nous terminerons par une critique simple de l’architecture proposée.
Gouvernance des données
Définition
La gouvernance des données a pour but de garantir la qualité de la donnée au sein d’une organisation ainsi que sa sécurité. Elle inclut notamment :
- La disponibilité des données
- Le contrôle des données
- La qualité des données (consistance, intégrité, véracité, …)
- La confidentialité des données
- La visibilité des données,
- …
Nous aurons donc deux axes complémentaires pour parler de gouvernance : un s’attachant aux processus de traitement de données (incluant le stockage) et l’autre centré sur la visualisation (mise à disposition des utilisateurs).
1 : dans cet article, nous allons essentiellement nous arrêter sur le premier axe.
2 : nous allons ici nous concentrer sur la définition relative à la gestion de la donnée, la dimension politique de la définition est sans intérêt pour notre propos.
Principes
La gouvernance des données est un concept multiforme. Elle dépend souvent de la démarche dans laquelle elle s’inscrit (volonté de l’organisation relativement à une législation, volonté de rationalisation des processus de traitement de données pour un département, …). On peut toutefois énoncer certains principes qui demeurent suffisamment indépendants du contexte parmi lesquels :
- Les données doivent être identifiées (origine, propriétaire, lieu de stockage, …)
- Les données doivent être classées (typologie, sensibilité, …)
- Les données doivent être garanties (qualité, intégrité, disponibilité, …)
- Les données doivent être sécurisées (sécurité des échanges, sécurité des traitements, confidentialité, …)
- Nous devons pouvoir identifier les traitements effectués sur les données (ex : data lineage)
Un cadre pour la gouvernance des données pourra être extrait de ces caractéristiques.
Dans cet article, nous n’allons pas nous référer à la notion de data contract telle que défini par Microsoft. Elle est cependant intéressante à approfondir pour disposer d’éléments complémentaires relatifs à la gouvernance des données…
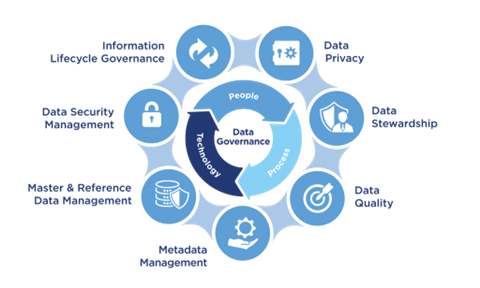
Framework de gouvernance
Un framework de gouvernance des données crée un ensemble unique de règles et de processus pour la collecte, le stockage et l’utilisation des données. Il permet :
- De rationaliser la gouvernance des données,
- De simplifier l’évolution de la gouvernance
- De maintenir la conformité vis-à-vis des politiques internes comme de la réglementation
- Simplifier et supporter la collaboration
Il permet également de garantir l’application globale des politiques et des règles de gestion appliquées sur les données.
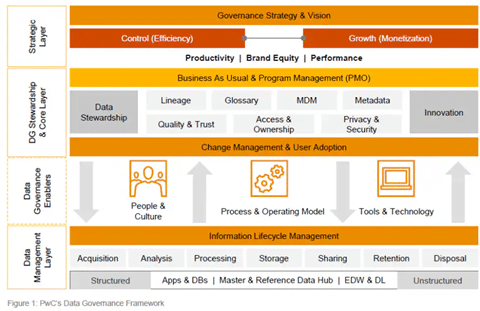
Un cadre de gouvernance doit opérer sur plusieurs niveaux :
Un programme d’intendance des données est la mise en œuvre opérationnelle d’un programme de gouvernance des données. Les gestionnaires de données effectuent le travail quotidien d’administration des données de l’entreprise.
Une gestion proactive de la qualité des données dans l’entreprise.
Processus formel de définition et de documentation des actifs de données dans l’ensemble de l’entreprise.
Une gestion d’entreprise des éléments de données critiques et partagés entre les systèmes de données.
Un inventaire défini et documenté des données qui doivent être sécurisées : qui peut y accéder et comment les sécuriser ?
La confidentialité des informations est un domaine vital de l’identification et de la gestion des risques. La nouvelle législation oblige les organisations à évaluer les efforts de conformité dans le traitement des données des clients.
La gestion des données/informations, de leur création à leur disposition. le cycle de vie des informations établit les normes, les politiques et les procédures de l’entreprise pour la conservation et la destruction des données.
Architecture proposée
Introduction
Nous voulons ici développer un système qui fonctionne en temps réel. Nous souhaitons tout particulièrement :
- Répondre aux exigences définies dans le framework de gouvernance de données
- Identifier les données (source, formes, …)
- Identifier les traitements et réaliser un lineage sommaire
- Sécuriser la donnée relativement à la sensibilité
- Identifier des soucis de « fuite» que l’on associerait à des traitements qui ne seraient pas maîtrisés.
Dans cet exemple nous reprenons les concepts de l’infrastructure as code (et plus généralement du everything as code) et implémentons l’ensemble des règles du framewok au sein même du système. Notre système repose sur un broker et l’ensemble des données échangées passent par ce dernier.
Principes
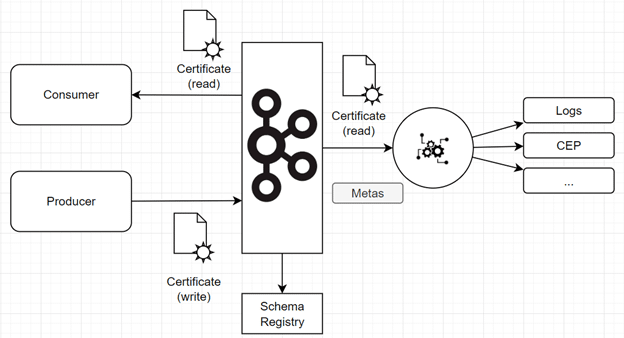
L’architecture consiste à ajouter un « observateur » (à droite sur le schéma) sur l’ensemble des topics disponibles. Cet élément va capturer l’ensemble des échanges (appelés événements) sur la plateforme. Il applique ensuite des traitements permettant :
- D’observer les échanges de données (tracing, télémétrie, …)
- De vérifier la sécurité et la compatibilité des échanges de données avec les règles de gouvernance
- D’appliquer des contrôles de qualité (format, volume, …)
- De détecter les violations de règles de gouvernance (via des approches Complex Event Processing)
Pour y parvenir, le système utilise un certain nombre d’informations :
- Les informations de l’événement,
- Les informations du canal sur lequel il est produit (ici les informations du topic, les certificats, …).
- Les règles décrites dans le code source du système,
- …
Information | Description | Source | Remarque |
Application source | Décrit l’application source émettant les données. | Certificats producer | Le data catalogue permettra d’ajouter les métas informations utiles aux échanges. Ces informations sont versionnées dans un VCS. |
Application destination | Décrit l’application destination de l’échange | Certificat consumer | Le data catalogue permettra d’ajouter les métas informations utiles aux échanges. Ces informations sont versionnées dans un VCS. |
Type de données et contexte | Décrit le contexte de la donnée, le type d’événement, le type de données et éventuellement le type de traitement | Topic | Ces informations sont gérées et versionnées par le schema registry. |
Meta information sur la donnée | Fournit une partie des métas informations sur la donnée. Nous disposerons tout particulièrement des informations relatives à l’instance de l’événement | Méta informations de l’événement | Ces informations sont gérées et versionnées par le schema registry. |
Information sur la donnée | Fournit les informations sur la donnée effectivement transférée. | Contenu de l’événement | Ces informations sont gérées et versionnées par le schema registry. |
La forme d’un événement est la suivant :
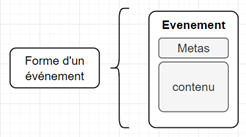
Les métas informations correspondent aux headers de l’événements. Ils peuvent donner des nombreuses informations et sont normalisés (*1).
Le contenu du message est également normalisé. Le format de chaque message est stocké dans le schéma registry (*2). Seuls les événements compatibles avec le schéma défini dans le schéma registry peuvent être émis sur le topic. Tout événement n’étant pas conforme à la spécification du topic sur lequel il est envoyé est rejeté (*3).
Ces éléments nous permettent de garantir la bonne gestion des métas données et la gestion de la qualité des données (en partie faite par l’intermédiaire de code review effectué sur le schéma décrivant les données et sur le code décrivant les traitements appliqués sur les données).
L’utilisation de certificats, et donc la sécurisation des échanges permet de répondre aux problématiques de confidentialité des données ainsi qu’à certains aspects de sécurité des données.
Le schéma registry permet de gérer la qualité des données échangées et, en partie, les cycles de vie des versions des données.
(*1). Les messages ne présentant pas l’ensemble des headers requis sont bloqués et des alertes sont envoyés aux différentes parties prenantes pour les informer du problème.
(*2). Les schémas de message sont également versionnés.
(*3). Le producer reçoit une erreur lorsqu’il tente d’émettre des événements qui ne correspondent pas au schéma.
Les traitements avals
Dans l’architecture proposée, le système détecte les violations des règles édictées dans le cadre de gouvernance. L’architecture n’interdit pas les opérations qui violeraient lesdites règles.
Ces détections sont faites par des traitements en aval de l’observateur, sur des streams de gouvernance.
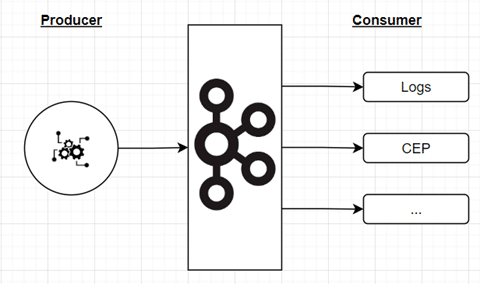
En aval du broker, côté consumer, un ensemble de streams vont implémenter les traitements dédiés à la gouvernance des données. Ces éléments peuvent être des compositions de traitements : ils sont en fait réalisés au travers de data streams (en utilisant des technologies telles que Kafka Stream ou Flink par exemple). Les sinks de ces traitements peuvent être :
- Des rapports BI,
- Dashboard de contrôle,
- Des bases de données,
- Des alertes/notifications,
- …
L’utilisation de matrices de sensibilités des données, fournit aux traitements avals, peut permettre de :
- Garantir la confidentialité des données,
- Garantir la sécurité des échanges en détectant les fuites de données
- …
Les données de référence et la gestion des cycles de vie des données sont réalisées au travers de :
- Schémas décrivant les événements,
- Règles dans le code,
- Ensemble d’outils intégrés dans les streams de traitement,
- Workflow, dont les spécifications sont codées, permettant d’automatiser les processus tels que la suppression de données une fois le période de rétention échue
- …
Ebauche de critiques de la solution
Bons points
L’architecture est complexe et demande la maîtrise d’un certain nombre d’outils en même temps qu’elle requiert un minimum d’automatisation afin de s’affranchir de tâches manuelles qui pourraient devenir excessivement chronophage (ex : gestion des certificats).
Il est important de souligner le fait que l’architecture se prête très bien aux prises de décisions automatiques et en temps réel. Ainsi, on dispose d’une architecture qui peut évoluer simplement au fur et à mesure que l’organisation gagne en maturité.
Mauvais points
La solution proposée présente l’inconvénient de ne pas interdire les échanges s’ils violent les règles de gouvernance. On peut toutefois l’adapter pour prévenir les violations. Il faut également noter que l’utilisation des streams peut être onéreuse. Il est nécessaire de choisir les technologies attentivement de manière à maîtriser les coûts.
On pourrait formuler de nombreuses autres critiques de la solution proposée mais pour des raisons de concision nous n’allons pas être exhaustif.
Conclusion
L’architecture présentée ici permet de répondre aux questions de gouvernance de données : après un travail amont de définition du cadre de gouvernance, nous implémentons les règles dans le code source du système. Ce dernier sera revu avant d’être déployé et pourra ensuite être audité.
La solution proposée permet de disposer d’un système capable de traiter les questions de gouvernance en temps réel. En normalisant les échanges dans le code, on dispose d’un système capable de s’auto observer et de détecter voire d’interdire les violations de certaines règles de gouvernance.
Ici nous avons traité du cas des flux de données inter applications. Nous n’avons pas évoqué les accès aux données directe par des utilisateurs comme cela serait par exemple le cas lorsque les données sont récupérées via des applications web ou mobile depuis des API REST et des jetons JWT. Le protocole OAuth2 couvre cet aspect et l’architecture proposée dispose de son équivalent pour les données émises par les handlers des API.





