

Le développement de logiciel fait référence au processus de création, conception, déploiement et au support des logiciels.
Depuis les balbutiements de l’informatique, les technologies ont beaucoup évolué, mais un préalable demeure : la qualité du code est essentielle.
Le concept de « clean code« , ou code propre, est comme un guide pour les développeurs à travers la complexité informatique.
Dans cet article, nous explorons cette philosophie du code propre, ses principes et son impact sur différents langages de programmation.
Ensemble, définissons le clean code, revenons à ses origines et explorons ses fondamentaux concrets.
La définition simple du "clean code"
Le clean code est un ensemble de pratiques qui visent à produire du code compréhensible, efficace et intuitif à manipuler.
Le travail du développeur consiste à écrire du code intelligible par des machines. Toutefois, dans le monde de l’industrie, être compris par les machines ne suffit pas : dans l’immense majorité des projets sur lesquels nous intervenons, un même code source est manipulé par plusieurs personnes. Et c’est là que tout se complique : se faire comprendre par des humains n’est pas aussi facile que de se faire comprendre par des machines.
En effet, pour qu’une application puisse évoluer correctement, il faut que son code puisse être compris, adapté et modifié par n’importe quel développeur. Si ce n’est pas le cas, le coût pour faire évoluer l’application va augmenter exponentiellement avec le temps… C’est là qu’on peut faire une distinction entre le code efficace et le code propre (clean).
Chacun d’entre eux se concentre sur des aspects différents du processus de programmation : alors que le code propre vise principalement à améliorer la lisibilité et la maintenabilité, le code efficace se concentre sur les performances et l’optimisation de l’exécution du programme.
D’ailleurs, comment mesurer la lisibilité du code ?
Mesurer la lisibilité du code
Comment déterminer si un code est clean ? Ou plutôt à quel point un code est clean ?
On peut notamment penser à Sonar, utilisé avec le langage Java, qui donne des indications sur la complexité, la vulnérabilité, la couverture de test de code rédigé.
Cependant, un outil informatisé ne pourra pas réellement déterminer à quel point le code sera compréhensible par un autre développeur, il ne donnera que des indications : le meilleur indicateur qui le prouve est le WTF/M, comme on le voit ci-dessous.
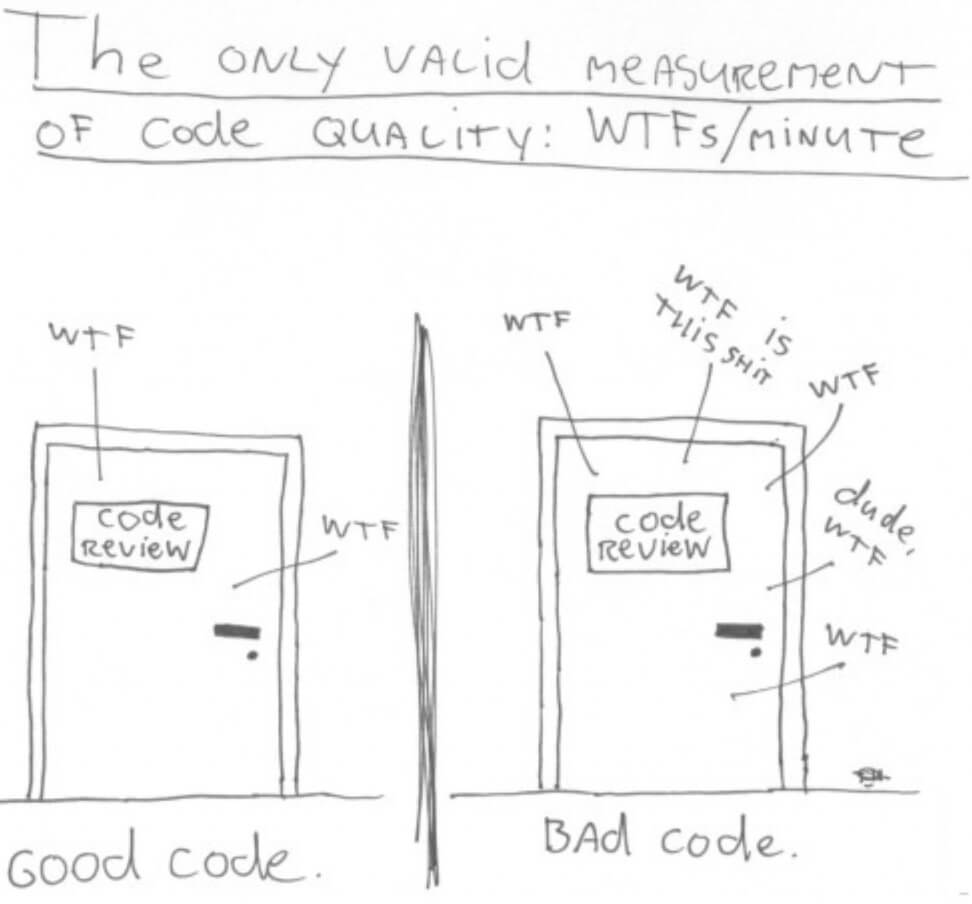
Au-delà du mème, l’illustration montre le but recherché par le clean coder : faire diminuer le taux de WTFs/Minutes, c’est-à-dire augmenter la lisibilité de son code.
Il existe toutefois des mesures que vous pouvez mettre en place pour améliorer la lisibilité de votre code :
- Documenter et commenter votre code, sans pour autant le polluer avec trop de commentaires superflus.
- Rester cohérent dans votre style d’indentation.
- Réduire le niveau d’imbrication.
- Ne pas garder les lignes codées “au cas où”.
Ainsi, un code clean sera lisible par le plus grand nombre de développeurs, ce qui évitera les incompréhensions par la suite. C’est le bon moment pour revenir aux origines du clean code.
Clean code : le livre
Des pointures du développement logiciel ont essayé de répondre à la question de la mise en place de normes de codage propre. Une des plus célèbres, Robert C. Martin (alias Uncle Bob), s’est penché sur les principes qui définissent un code source de qualité dans son livre Clean Code : A Handbook of Agile Software Craftsmanship, publié en 2008.
Certes, ce livre n’est pas récent, mais il a inspiré et inspire encore des générations de codeurs.

Les principes développés dans ce livre sont des principes généraux, agnostiques du langage de programmation utilisé. Il ne s’agit pas de règles à appliquer strictement, mais plutôt d’aides ou d’inspirations.
Résumé de Clean Code : A Handbook of Agile Software Craftsmanship
Robert C. Martin nous propose donc un certain nombre de principes à mettre en place pour s’assurer que notre code soit propre (clean) :
- Suivre des conventions reconnues pour obtenir le code le plus universel possible
- Laisser le code plus propre qu’on ne l’a trouvé, un principe aussi connu sous l’expression “la règle du boy scout”
- Respecter les règles de design fondamentales, comme conserver les données configurables à haut niveau ou d’éviter de sur-configurer ses fonctions
- Favoriser la compréhension du code, en restant cohérent, explicite et en facilitant la visibilité des dépendances des différentes fonctions
- Respecter les règles de nommage : pas d’ambiguïté sur les noms de fonctions et de variables, des noms recherchables, et des distinctions claires entre les entités
- Mettre en place des fonctions courtes, qui ont un usage unique, sans effet de bord et avec le moins d’arguments possible
- Soigner les commentaires, en étant clair, concis, en évitant la redondance et le bruit inutile
- Structurer le code source en soignant particulièrement les indentations, en déclarant les variables, et en gardant le code structurellement cohérent, par exemple en cachant les structures internes pour plus de lisibilité
- Réaliser des tests rapides, indépendants, utiles, répétables et faciles à lancer.
Robert C. Martin nous donne également les 6 indicateurs d’un code insuffisamment propre, qu’il appelle “code smells”, et qui sont donc à surveiller et éviter. Ainsi, le code smells est :
- Rigide et donc difficile à faire évoluer.
- Fragile, présente de nombreux dysfonctionnements.
- Immobile, c’est-à-dire qu’il est difficile voire impossible de le réutiliser pour d’autres projets.
- Inutilement complexe.
- Répétitif.
- Opaque, difficile à comprendre.
Les principes SOLID
C’est un sous-ensemble des principes promus par Robert C. Martin, qui font référence à 5 principes de base pour la programmation orientée objet :
- Single Responsibility Principle ou principe de responsabilité unique : chaque composant n’a qu’une seule et unique responsabilité.
- Open Closed Principle, ou principe d’ouverture et fermeture, qui indique que chaque composant doit être ouvert à l’extension et fermé à la modification.
- Liskov Substitution Principle, le principe de substitution de Liskov, qui précise que chaque classe fille doit pouvoir être substituée par sa classe mère sans conséquence.
- Interface Segregation Principle, ou principe de ségrégation de l’interface : aucun objet ne doit être dépendant de méthodes qu’il n’emploie pas.
- Dependency Inversion Principle, ou principe d’inversion de la dépendance : les composants de haut niveau ne doivent pas dépendre de composants de bas niveau.
Clean code : les principes
Finalement, que retenir de tous ces principes ? Comment établir des normes pour le clean code ? Nous choisissons d’en garder trois, absolument cruciaux :
Le code doit être simple
C’est la première caractéristique du clean code. Il faut éviter autant que possible de complexifier le code en se demandant si la solution implémentée est la plus simple pour répondre au besoin. Plus le code est simple, plus il est lisible, et donc plus il sera maintenable dans le futur. Il existe un acronyme qui nous aide à nous souvenir de ce principe : KISS (Keep It Simple Stupid).
Pour cela il convient d’éviter la sur-configurabilité et de proscrire tout ce qui est écrit « au cas où ».
Le code doit être ciblé (focused)
Un morceau de code doit être écrit pour résoudre une seule et unique problématique. C’est valable à tous les niveaux d’abstraction du code : méthode, classe, package ou module. Le travail de réflexion autour du découpage du code doit permettre de déterminer les bonnes abstractions.
« Bad abstraction is worse that duplication”
Deux morceaux de code peuvent être identiques : s’ils représentent chacun des concepts différents, il est préférable de conserver cette duplication “accidentelle”. Dans ce cas, le principe DRY (Don’t Repeat Yourself) ne s’applique pas.
Ainsi, les responsabilités de chaque bout de code seront correctement réparties. On retrouve ici les principes SOLID, notamment le “Single Responsibility Principle”.
Le code doit être testable
Si le code est simple et n’a qu’une seule responsabilité, il devrait être facile à tester. Les tests représentent une sécurité contre les régressions qui peuvent intervenir lors de l’évolution du code.
Ils constituent également la documentation qui permet aux autres développeurs de comprendre le fonctionnement du code testé. Ils doivent être écrits de préférence avant le code productif (TDD) et être dans la mesure du possible automatisés.
On peut présenter l’acronyme FIRST qui caractérise les “clean” tests :
- Fast (rapide),
- Independent (indépendant),
- Repeatable (répétable),
- Self-Validating (auto-validé),
- Timely (opportun).
Passons à présent à une méthode concrète pour intégrer le clean code dans votre entreprise.
6 étapes pour intégrer le clean code dans son entreprise
Si vous souhaitez introduire les méthodes du clean code dans le fonctionnement de votre entreprise, il peut être bon de faire appel à des experts en la matière. Qim info aura le consultant qui répondra à votre besoin particulier.
Voici un ensemble de recommandations pour optimiser vos productions logicielles grâce au clean code :
- Rappelez les principes du clean code aux développeurs afin que toutes vos équipes soient sur la même longueur d’onde. C’est également le moment opportun pour envisager une formation ou un séminaire sur le sujet.
- Implantez une politique de clean code en définissant clairement les règles prioritaires les plus importantes dans le cadre de votre activité. Par exemple, en uniformisant les noms de variables ou de fonctions que vous utilisez régulièrement.
- Documentez le code produit par vos équipes afin qu’il reste lisible dans le temps.
- Intégrez un Linter, un utilitaire qui vous permettra de maintenir un code uniforme à partir de règles que vous aurez configurées et pré-définies. Il en existe plusieurs pour les différents langages de codage.
- Organisez un suivi, en demandant à vos développeurs de revoir régulièrement leur propre code pour s’assurer de sa propreté, et en organisant des mises au point d’équipe.
- Retravaillez les anciens codes. Ce n’est pas parce qu’ils n’étaient pas clean auparavant qu’il ne faut pas leur faire suivre votre transition !
Le clean code appliqué aux différents langages
Les règles du clean code restent les mêmes sur tous les langages informatiques, mais voici cependant certaines des particularités propres à chacun des langages.
Python
Le plus important sera le nommage des fonctions et variables, ainsi que l’évitement des doubles négatives.
Java
Si Java ne propose pas de structure de projet par défaut, il serait cependant intéressant de suivre une structure que vous aurez prédéfinie et qui restera constante.
Javascript
Le nommage des différents éléments est le plus important pour vous permettre de développer du clean code sur Javascript.
C#
Il est particulièrement important de faire attention aux doublons en code sur C#.
html
Les balises redondantes et en double sont vos principaux ennemis sur html pour un code clean.
Ruby on rails
Le nom des variables est une fois de plus primordial. Nous vous recommandons notamment de garder le même vocabulaire pour des variables similaires.
Il existe d’ailleurs des outils utiles pour le clean code, dont certains sont spécifiques à tel ou tel langage.
Les meilleurs outils pour “clean coder”
Il n’existe pas d’outil qui puisse implanter du code clean ou nettoyer automatiquement vos productions, en revanche certains outils peuvent vous faciliter la tâche et vous donner des indicateurs à suivre.
- Des Linters : comme nous l’avons précédemment évoqué, ce sont des utilitaires qui vous permettent de pré-définir des règles que votre code devra respecter. Il en existe des dizaines pour chaque langage : checkstyle pour Java, clinton pour Javascript, htmlhint pour html, flake8 pour Python,…
- Maven est un outil de structure de code pour Java
- Rubocop analyse et formate votre code sur Ruby on Rails
- Prettier automatise le formatage de votre code
- SonarQube analyse le code pendant la phase de compilation et s’utilise avec les langages de programmation les plus couramment utilisés dans le développement logiciel (Python, C#, Java…).
- Jenkins (ou un autre outil d’intégration continue) : l’intégration continue et l’automatisation des tests aident à maintenir la qualité du code tout au long du cycle de développement.
- JUnit (ou tout autre framework de tests unitaires) : écrire des tests unitaires est une composante clé du clean code. JUnit est un framework populaire pour les tests unitaires en Java.
Les méthodes clean code sont ainsi des guides qui vous permettent de rendre votre code plus simple d’utilisation, plus lisible et plus pérenne. Alors, qu’attendez-vous pour, vous aussi, vous mettre au clean code ? Nos experts sauront être à votre écoute pour vous conseiller dans votre démarche.
Pour en savoir plus, nous vous invitons à consulter notre article sur les étapes de développement d’un logiciel sur mesure.
Benoît.


